
How Enterprises Will Learn Like Models Do
The Unlock, The Evolution, and The Opportunity

Every foundational company now has an Agent SDK. OpenAI has AgentKit. Anthropic has Claude Agent SDK and Gemini has ADK, and a wave of startups are chasing the same primitives tools, memory, context, and actions.
The real unlock isn’t that anyone can build agents, it’s that enterprises can finally stop consuming AI and start shaping it.
The Unlock: Experimentation as a Native Enterprise Capability
Agent SDKs (ADK) didn’t just make it easier to build agents. They made it possible for enterprises to experiment. For years, enterprise innovation followed the same SaaS pattern —
PoC → Procure → Pilot → Integrate → Operate.
ADKs flipped that script. The new motion is
Build → Try → Evaluate → Iterate → Integrate → Operate.
That shift is profound. It moves the enterprise from being a consumer of tools to a creator of capabilities. With this, Enterprises can
Separate Signal from Noise
Fail fast
Build a new muscle around value creation and capture.
This unlock comes with its own set of challenges.
The Evolution: Context and Change Are the Real Moats
Need for “Systems of Context”
Experimentation is easy. Evolution is hard. As Vignesh put it: “The right context at the right time is critical. Relevant context significantly improves performance.” Context is how a business thinks, the blend of knowledge, rules, and processes that shape every decision. ADKs let us wire tools and memory, but not how an enterprise reasons. It’s accumulated judgment, handling of edge cases, and shaping processes. It lives in documents, systems, and people’s heads.
And until enterprises take control of this “system of context,” agents will remain powerful in prototypes and brittle in production.
Enterprise stack itself is evolving, painfully and beautifully.
Most large organizations run on decades of SaaS infrastructure.
Overhauling all of it with agentic systems is unrealistic;
Making it machine-ready through MCP servers is iterative and needs more work.
On top of that, every model release changes what’s possible; reasoning improves, but reliability shifts. It’s both a pain and a grace: a pain because stability is elusive; a grace because there is no lock-in yet. The hard part isn’t adopting AI, it’s keeping up with it.
The Opportunity: Learning Enterprise
Why RL Is Hard
Andrej Karpathy described reinforcement learning as “sucking supervision through a straw.” Checkout his talk here
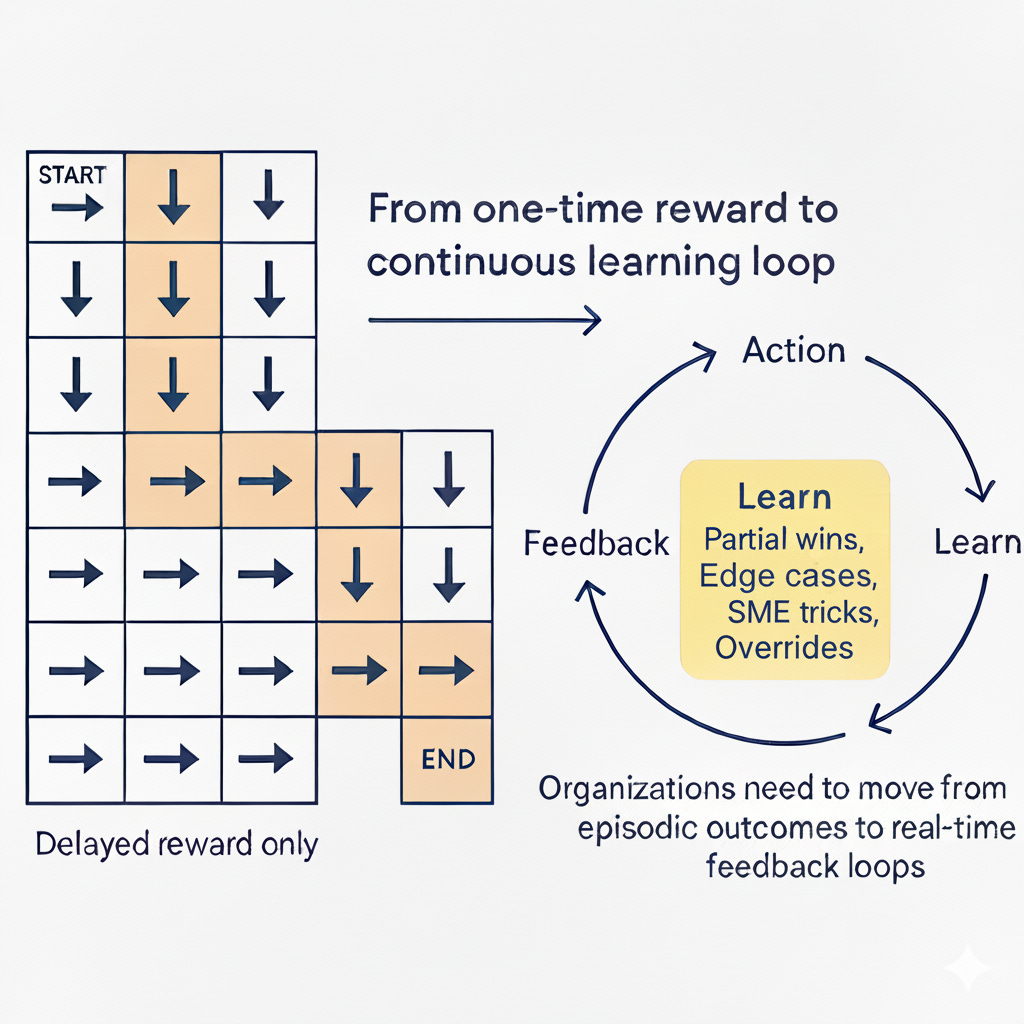
You run thousands of experiments, take hundreds of wrong turns, and at the end of it all you get a single signal a number that says good or bad. Every decision that led to that result, good or bad, gets weighted the same.
That’s how most organizations learn, too.
Every quarter or year, orgs look at outcomes —> NPS, revenue, adoption and try to assign credit to decisions made months ago. Just like reinforcement learning, it’s noisy, delayed, and lossy. And just like models, organizations mistake correlation for causation. A win becomes a template. A failure becomes a rule. We pay less attention to which step in the trajectory actually mattered.
If reinforcement learning is hard for models, it’s even harder for enterprises because the feedback loop isn’t just delayed, it isn’t reflected.
Why Enterprises Should Care
RL doesn’t teach in context it only rewards the final outcome. Humans, on the other hand, learn through process supervision they reflect, review, and adjust at each step. We need mechanisms to assign reward, provide feedback to the “right direction” even when the final outcome isn’t perfect. They need context-aware evaluation, not end-of-quarter judgment. That’s the direction enterprises must evolve the agentic systems to unlock ROI.
Preparing for RL at the Enterprise Level
To prepare for this shift, enterprises should focus on three design principles:
Feedback at every step. Build process-level metrics that assess reasoning and judgment in real time, not just final KPIs.The faster you close the feedback loop, the less noise you amplify.
Reward reflection, not just results. Create evaluation systems that value learning signals, how quickly teams identify failure modes, what they infer from them, and how those insights propagate.
Design for adaptive reinforcement. Teach agents and teams to adjust based on intermediate feedback, not static goals. Reinforcement shouldn’t come from quarterly reviews; it should emerge from live business signals and human judgment.
Conclusion
ADKs gave enterprises speed.
→ Context gives them precision.
→ Learning will give them power.
The winners won’t be those who build agents, but those who build agents that learn.
The unlock you describe, moving enterprises to build, try, and iterate with Agent SDKs rather than just consume, is trully the most profound shift for AI engagement, a genuinely insightful observation that resonates deeply.